

6 Ways to Offer Custom SQL Support in Your Product
A breakdown of the downsides, problems, and solutions of offering SQL support for your product
You collect some customer data or generate something for your customers. And you want to make this data queryable in order to provide your customer flexibility to extract their own insights, like Stripe Sigma. Depending on your data storage, volume, ingestion rate, retention, and usage patterns, there are many possible ways to do it. The query methods include free-text search, visual query builders, slice-dicing time-series data filtering, a DSL (domain-specific language), and the good-old SQL.
As our love for SQL can be understood from our product, Resmo, naturally, we will brag about SQL in this blog. Why would you let your customers actually use SQL, though? Mostly, if you are going with a query language and not visual filters, SQL would be the obvious, safe choice, as nobody gets fired by buying IBM. Some do not like SQL, finding it outdated, table format restrictive, too verbose, and believing they can do better than SQL, I’d still prefer SQL. Many also have adapted GraphQL in their APIs for customer query flexibility, but with multiple relations and data sources, it’s easy to have an N+1 problem.
In any case, letting customers run arbitrary code in your product is always a security risk you need to be prepared for. Remember when Apple’s CoreGraphics PDF parser was exploited to emulate logic gates?
Although there are short sides to SQL, and you could probably do better in some cases, it’s most likely a good overall choice for a query language to integrate into your product as it will be familiar to many people. There are multiple ways of providing SQL in your product, each having its own pros and cons. Let’s see:
1. No-join, Single Table SQL
SELECT * FROM users WHERE name = ‘Mustafa’ is a valid SQL; not every SQL has to have the joins or complicated expressions in them to be useful. Depending on your data store, use a parser to convert your SQL to an AST and query this data from your store. Because a single SQL statement without joins is a projection with boolean filters and/or aggregations in a single table, most observability systems provide this feature with dropdowns.
As a simple example, filters match a hostname and availability zone and aggregate the average CPU utilization. Most data stores would support this, including Elasticsearch, MongoDB, InfluxDB, and regular RDBMS like MySQL and Postgres.
However, many tools like to provide more intuitive visual query builders for this feature, showing dropdowns to filter boolean expressions fields and aggregations. But some allow you to write your own queries too. One example tool that does is New Relic, NRQL, which has superb auto-complete, and I prefer to write it that way compared to visual query builders because it's faster, and I can write a bit more complex boolean logic and multiple aggregations in one query. Even this kind of flexibility can be a competitive advantage to you. Another example is Elastic, which translates SQL queries to gigantic Elasticsearch JSON. Amazon’s fork, OpenSearch, also provides a similar SQL feature.
So, suppose you decide to embed that kind of semi-SQL in your product. In that case, all you need to do is find some SQL parser (or write your own with ANTLR, are you alright?), parse it to boolean expressions for filters, projections, and table name, and translate that to a simple query in your favorite backend data store and transform the response to a tabular format. This is mostly a safe choice regarding security because you are in control of what’s being queried - unless you allow arbitrary functions or use string concatenations to build a query.
2. CLI Tools
Some useful CLI tools let you query CSV, JSON, and Parquet files. Many people like such tools because they allow you to get quick insights from your data sitting on your downloads folder exported from somewhere, and you are too lazy to run ETL on them (virtual-hug). Importing those CSVs to Excel or Google Sheets is excellent for basic exploration, but you know you can do much better if you can run SQL. You can even join data from different CSV files without needing to use VLOOKUPs.
Multiple CLI tools provide similar functionality to query files in your computer.
- q - Python-based, seems fast due to caching
- octosql - Go-based, in addition to files, it can also query Postgres and join them
- dsq - Supports CSV, JSON, Parquet, YAML (oh, no) ORC, Excel, some Apache Error Logs
- textql - Go-based import and run queries
- sqlite - The good old SQLite binary can import CSV files and query in 2 commands.
I will not go into the differences between each tool, as they are mostly similar, differing in file formats and performance characteristics. To integrate these tools into your product, you’d need to prepare data as supported file formats somewhere and invoke those programs. Invoking binaries in runtime for each request is usually a security risk if it takes arbitrary inputs, so you need to explore the attack surfaces. Can those tools read other files and execute additional programs? The alternative is to use those CLI tool's code as libraries, but it’d require more work as most of them would optimize for the CLI use cases.
3. Parse SQL and Fetch Data Yourself
Congratulations, you made a query engine. It’s most likely that you will fail. Or it will turn out to be an awesome open-source product that will eventually change the permissive license to business something to fend-off AWS. In either case, this is a huge task. Not only do you have to build an extensive parser (the sane choice would be leveraging existing ones, but you are not sane, are you?), you need to compile that to a query plan that would actually be executed to fetch the data. While you are researching, don’t forget to refresh your knowledge of Relational Algebra. Here is an example:
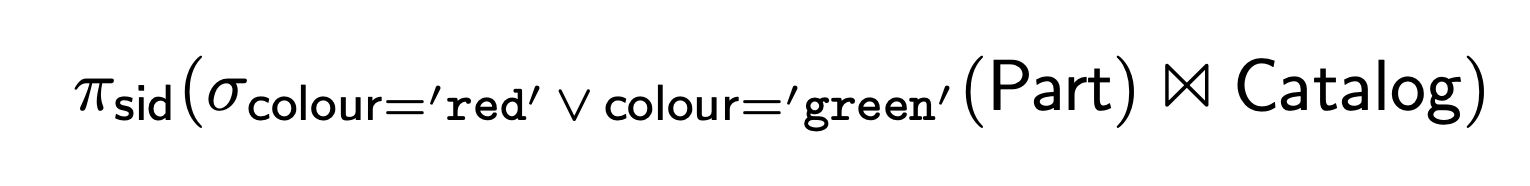
Some existing SQL parsers include:
- JSqlParser: Java-based SQL parser we used in a pet project - that we’d like to open-source this quarter
- libpg_query: Parses Postgres Syntax, used by many projects including pganalyze, DuckDB
- ANTLR SQL Grammars: It even comes at many flavors, though half of the job is managing to run Hello world with ANTLR
Now you’ve parsed the SQL to a syntax tree. What about now? You need to somehow convert that AST to a Query Plan; good luck with that! Your initial plan would suck. After all, you’d most likely forget to rewrite your joins to make it more effective because you did not make use of any statistics information. Also no parallelism. You could do much better. See how Apache Drill makes use of query plans or dig deeper with Apache Calcite with this awesome blog, which we will mention in detail later in this post.
Apache Calcite powers most of the big data tools that let you run SQL on data on HDFS, S3, or other distributed storage. When I was at the university, there was a hype of other big data tools, such as Hadoop and Spark, to perform every analysis using Map-Reduce on a massive scale and shuffle GBs of data over the network. However, all the examples I saw back then were to calculate word count on text files, and unfortunately, it did not spark any interest in me to really grasp its actual capabilities. I’m sure there were much more sensible use cases of MapReduce, but I’m glad the industry thought, “What if we use distributed SQL and give up ACID” and turned the query execution to map-reduce instead, like Spark. So, your own SQL engine is actually a viable option only if you are determined to make a competing distributed SQL engine project. You can even hire and entertain some graduate students for a long while.
4. Proxy the SQL to the Actual Database
Postgres and MySQL are already great databases. Or other databases that support any flavor of SQL. Databases today are much different from the last 15 years, support efficiently querying JSON, and GIS, and they can even be real-time, pushing updates to the clients, and can be sharded for horizontal achieving planet-scale (ba-dum-tss). They all are beautiful.
So, if you want the let your customers run queries, what can be a better solution to provide your customers access to the actual SQL database, right? It seems obvious. There are multiple things to decide and solve, though.
The table design is the first one. Database or table per customer or shared tables with row-level security? Leaving the user management to the database would require a separate connection for each, though, and many databases don’t like that and have external proxies or poolers to handle thousands of concurrent connections. (Most likely, you’d wish you had thousands of customers instead before facing connection scalability issues, though). You can even go ahead and expose the JDBC to the customers.
Security is a big issue; even with the restrictive rights granted on an actual database, there are hundreds of functions and utilities to use, and properly isolating customers and ensuring integrity might be a big issue. There were a few big vulnerabilities found this year on managed databases, including major cloud providers AWS, GCP, and Azure, that led to lateral movement. The best bet here would probably be running database instances per customer in tightly controlled containers and virtual machines with minimal interaction with outside.
Another issue is the timeshare; how would you ensure queries from customers do not saturate the database servers and starve the other customers of resources? The quickest solution would be to use containers per customer with CPU and Memory limits in a shared cluster. However, it might be a huge cost item unless you do not oversubscribe CPU - assuming you are not a database hosting provider, you just need customers to occasionally run some SQL.
5. In-Memory SQL Libraries
Some libraries allow you to read data into memory as language-native structures and let you run SQL on them. Depending on your data size and use cases, they might be viable options. In this section, we will show several options.
SQLite
As you might have noticed from recent blog posts and products, SQLite is very popular now. There are many known use cases for it: Android, the weird Expensify server, Apple using it in many native applications to keep state, Microsoft, Adobe, and many others. Why? Because it’s dead simple to use and integrate reliably. SQLite links to your program do not require a separate server running, simplifying most of the deployment woes of traditional database servers.
There is a great page on when to use SQLite. As it was not meant to run as a server application, people found many creative ways to run it in a distributed fashion. Cloudflare D1 provides customers to run SQLite at the edge. rqlite combines Raft to achieve consensus among multiple instances. Litestream is another example of backing up your databases to object storage continuously and reliably.
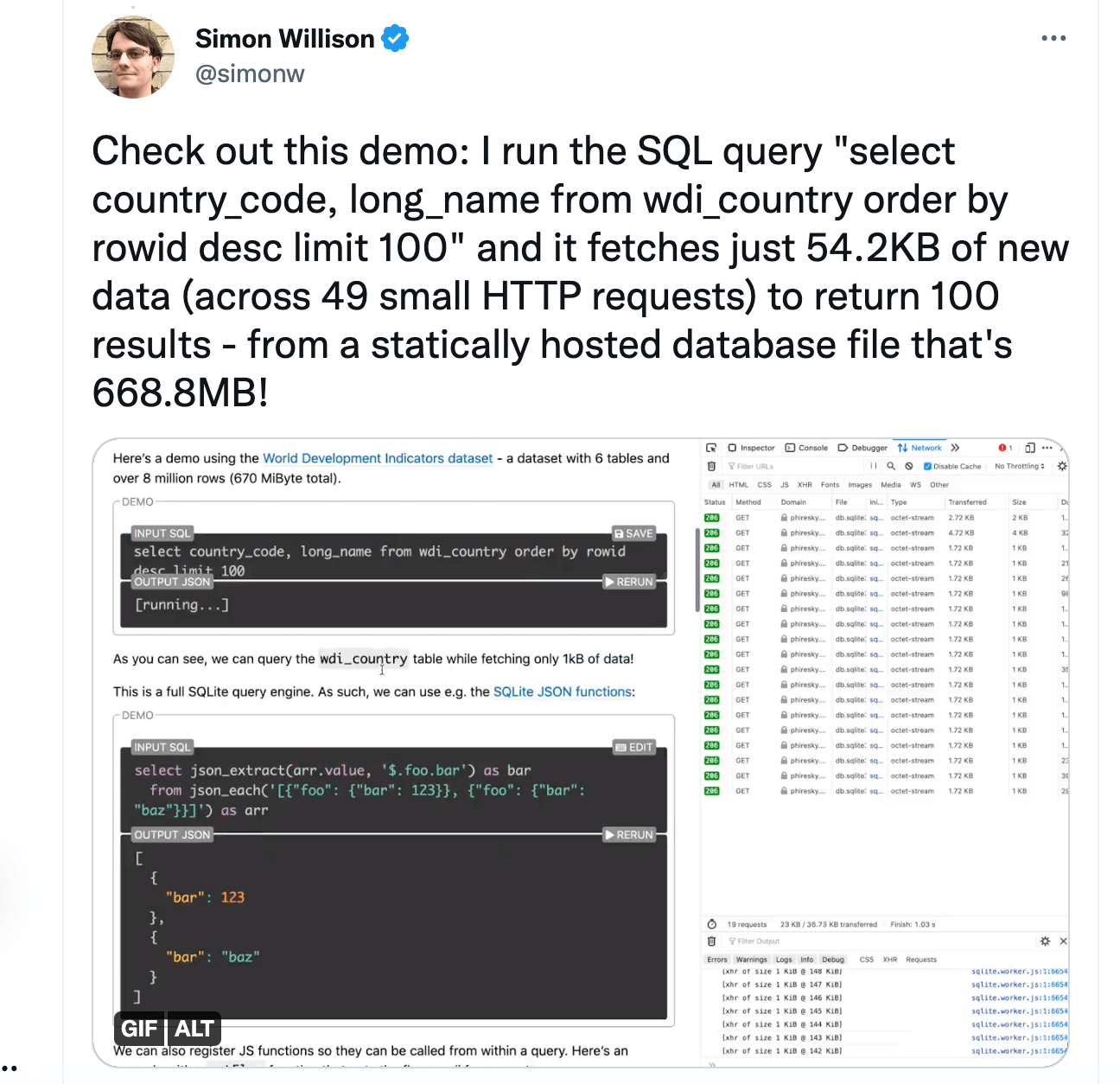
As you can see, many people are finding lots of use cases for integrating SQLite into their products and can be a viable option for you. It also supports saving data to disk, not just in memory. An innovative project that hosts the data on a server uses sql.js to run SQLite in the browser and fetches only the required pages with HTTP Range queries.
DuckDB
DuckDB is a recent, modern alternative to query data. It can import CSV and Parquet files easily, and it can also be used to connect external data sources. They even claim it can query the data in Postgres faster in an analytics use case.
Its main difference is that it assumes OLAP use cases, where huge amounts of data are processed to provide some sort of aggregations or joins among tables. To do so, it uses a columnar-vectorized query execution engine, compared to traditional databases where each row is processed individually. Otherwise, DuckDB operations and use cases are much similar to SQLite; it also runs in the same process as your application.
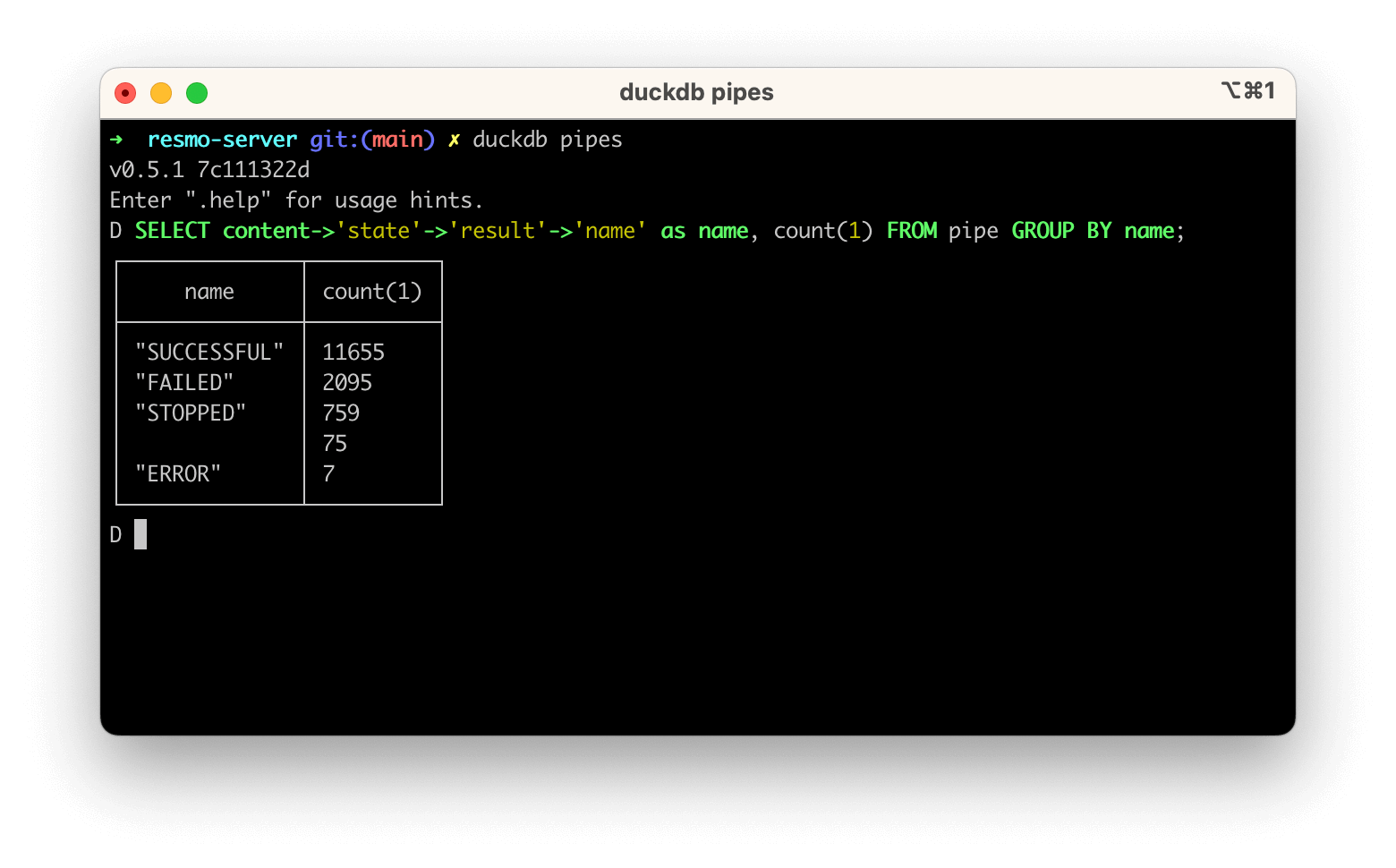
To embed in your application, if your data is stored somewhere else, you can easily import it to a DuckDB using built-in CSV and Parquet import functions from S3. Alternatively, you can use Appender for improved import performance. In addition, it also allows querying JSON similar to Postgres functions, which can be helpful for nested data we have nowadays. It can even compile to WASM to run in your browser! There might be a case for you, too.
LINQ
There is no viable way to propose Linq to your customers, but it’s an honorable mention. I was in high school when Linq was first introduced to the C# language. It was amazing. Too bad I did not have any chance to use it, though. LINQ allows you to query the in-memory data with something close to SQL.
If you chose to leverage LINQ in your product for customer query capabilities, as I’m not familiar with C#, I’m not entirely sure what would be the best way. There seems to be a somewhat good option, but still, it’s not accepting SQL string, as LINQ is actually C# code. Another unusual way would be to generate a valid C# code with the customer’s query, which would possibly result in an RCE in 5 seconds. LINQ is more synthetic sugar for traversing lists, similar to Java streams and Kotlin collection utilities in function than as a generic SQL executor, but I wish Java had an equivalent.
PartiQL
It was introduced by AWS in 2019 with a nice blog post. It’s a query parser and turns the AST into a Query execution in Kotlin. Here is an example code that lets you query data on S3. So you can swap the underlying value resolution for tables with any storage. There is also a Rust-based implementation on the way. PartiQL’s main strong points are First Class Nested Data and Data Storage Independence. PartiQL is SQL-92 compatible but has extensions to query nested data easily without using expand functions.
Interestingly, PartiQL is more known for the AWS services that support it. Mostly tools that support it normally have non-friendly query capabilities DynamoDB or QLDB. But, both of those tools PartiQL support do not allow JOINS or inner queries because PartiQL is used as a friendlier way of writing queries that translates to tool-native queries. So your queries might end up scanning all tables.
If you want to integrate PartiQL into your program to provide custom implementations for resolving variables and functions and it can query your data in memory. The latest version of it also allows query planning improvements. You still need to think about resource exhaustion, as with all the options working in memory.
Apache Calcite
As mentioned early, Apache Calcite is the defacto tool for parsing and optimizing queries. It’s used by many projects. Apache Drill lets you run distributed SQL queries on many sources, including S3, HDFS, Elastic, HBase, and many others. Drill leverages Calcite to parse the query and optimize it but executes the query plan in a distributed fashion. I used it in many cases to query unstructured data on S3 and locally, mainly because it allowed discover schema on the fly. But, its development of it was stalled for a while until recently. Another widespread Calcite implementation is Apache Flink, where Calcite is also used similarly, but it also allows SQL on streaming data, which can allow exciting use cases, like real-time dashboards or fraud detection.
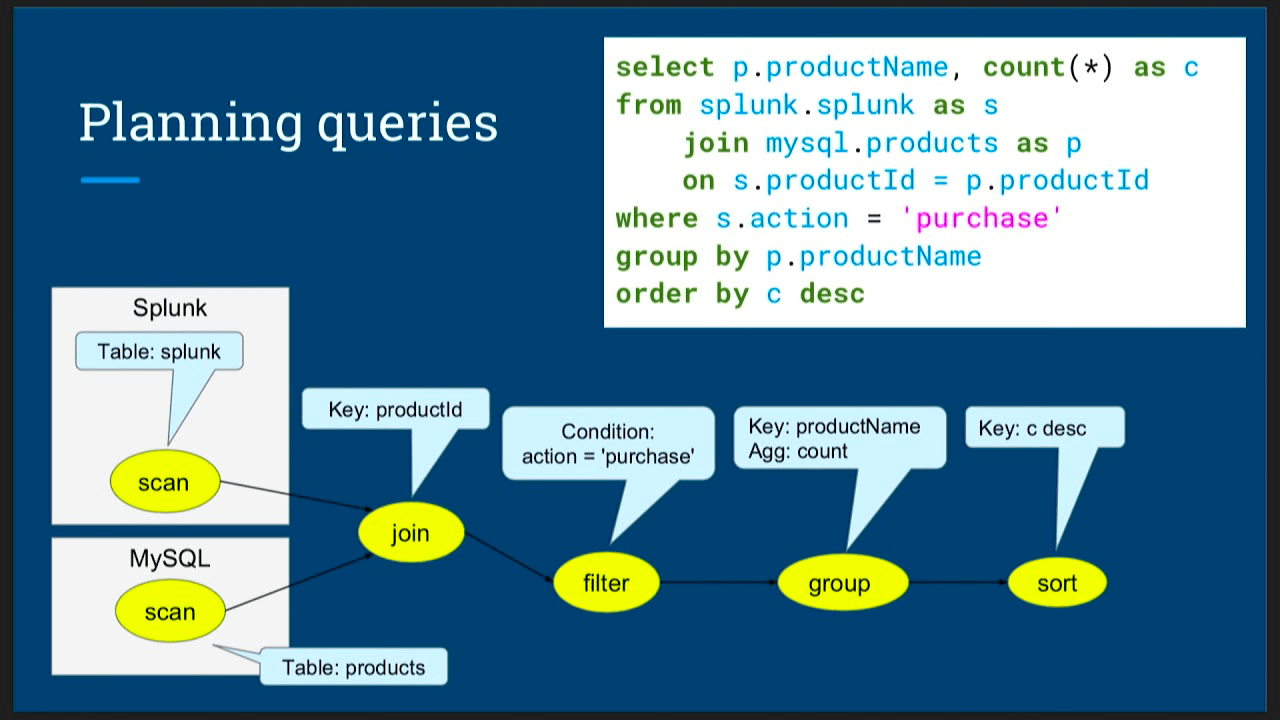
If you set out to build something based on Calcite, there is a great, detailed tutorial based on the CSV adapter. The tutorial describes how to define a model for schemas, scannable tables (basic) and filterable tables (predicate push-down), and relational operators. There is also another way to query in-memory objects in arrays by using ReflectiveSchema.
6. Pluggable SQL Engines
Presto / Trino
Presto was born out of Facebook; similar to Apache Drill, as we mentioned before, is a distributed SQL engine for querying the data lakes. It’s ANSI SQL compatible and used by many companies around the world. Trino is a fork of Presto because of governance disagreements between the original creators and Facebook. As a result, Presto is now trademarked and in Presto Foundation as a member of the Linux Foundation. and the fork originally named PrestoSQL was renamed to Trino to avoid further legal disputes. You know, the usual open-source drama when time passes and commercial activities surround the projects.
Anyways, relevant to our use case, I’m not sure whether Presto or Trino is the better choice as of now, but they both have the SPI (Service Provider Interface) to implement custom connectors, types, functions, and more. As always, you need to secure it for multi-tenancy; deploying isolated Presto clusters per each customer will not likely scale due to its overhead. There are options for access controls, but as they are complex software, you’d still need to be careful about exploits that might lead to exposing private information, breaking multi-tenancy, RCE (remote code execution), or even lateral movements.
AWS Athena
Athena is also based on Presto (maybe Trino now?), but it also allows you to use Lambda functions as connectors. You can write custom functions to query data somewhere or use it to query S3 if your customer’s data is there. It’s serverless and charges by scanned GBs, regardless of how long your query runs, unlike Snowflake. Although it’s fully managed, you’d still need to work out how you’d lay out the data in S3 or another store and the permissions. If you are going to implement custom connectors, depending on invocations and data size, Lambda invocations also can be a considerable cost.
Conclusion
I’d like to thank you for reading this so-far or just fast scrolling to this part looking for a TL; DR. You built a platform that has some data for customers through multiple sources (in our case, cyber-asset configurations like virtual machines, databases, users) and although you have processed this information in your product’s domain, you also want to give your customer ability to query this collected data for even greater flexibility, but also in a secure and scalable way. Using a form of SQL would be a good choice for familiarity.
You can either:
- Have simple filtering and aggregation on a single table backed by your datastores or invoke some CLI tools that can already execute arbitrary SQL on files on disk
- Use in-memory tools like SQLite or DuckDB
- Leverage lower-level pluggable tools like PartiQL or Apache Calcite
- Use distributed SQL query engines like Presto; or go mad and build your own SQL engine.
There is no golden solution to your needs because of varying data size & access patterns in your product and domain. In-memory options might not scale for more extensive data, and leveraging big-data toolsets might not be as responsive, directly using traditional RDBMS might have security concerns.
However, with all solutions, you need to solve common problems: How to scale this query capability? Also, how do we secure arbitrary code execution initiated by customers? These are big questions, but answers would depend on your product, domain, and customer profile and would most likely include tradeoffs.



